8:caformer的复现
概述
我们进入OSformer的复现,论文名称为Cross-domain-aware deep unfolding transformer for hyperspectral image super-resolution,提供的源代码https://github.com/Caoxuheng/HIFtool,这是一个高光谱融合方向的一个项目融合包,里面提供了多种方法,大致分为三类:model-based,supervised,unsupervised.我们的OSformer就是基于监督学习的一个方法
数据集
在文件夹multispectual image dataset中,我们可以看到一共有如下的五个文件夹,分别是
- CAVE
- chikusei
- Pavia
- QB
- xiongan
我们按照文件夹里面的md文件进行下载
bug调试
20260225
经过了一个春节小长假,调试的进度需要重新找回来。
由于我们的笔记本的32G的内存不足以加载需要60G内存的程序,而在Linux中出现killed报错,我们在autodl中新建了一个实例,用以解决问题。
autodl的一大好处是,其中的内存有120G,远大于我的电脑的32G,云端的CPU和内存几乎可以带动常见的所有的net。
这是我在autodl运行的内存的监控,可以看到预加载的过程是需要加载很大的数据的,这一次的复现是我在云端进行使用autodl的一个尝试。
但是由于出现了BUG,而且是长期没有解决的一个bug,所以我们要对其进行深度的分析和尝试,这一次的整个的报错的命令如下: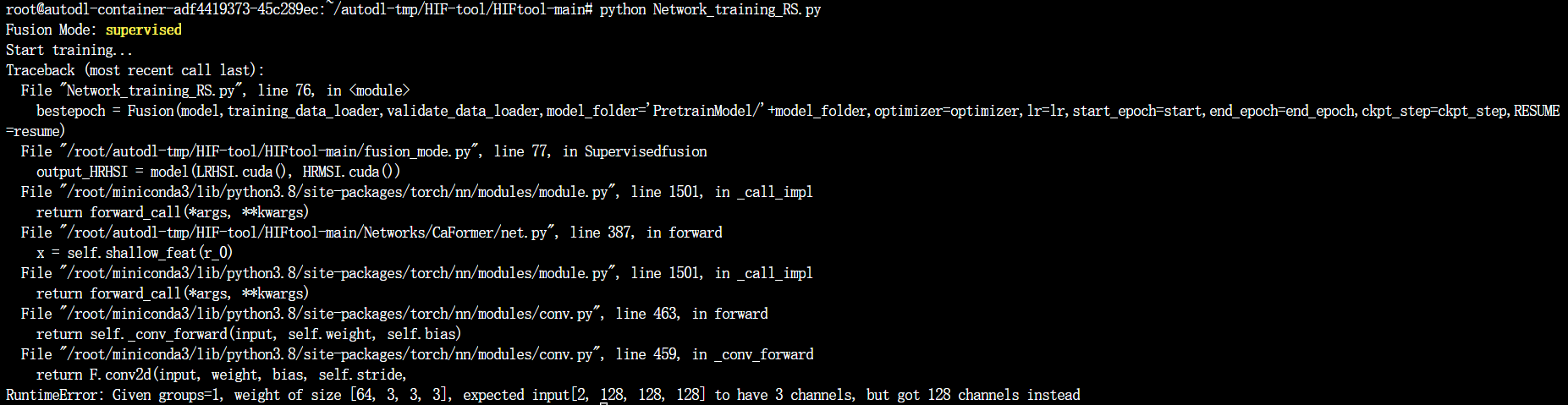
我们看报错的定位,是一个RunTimeError
File “Network_training_RS.py”, line 76
bestepoch = Fusion(model,training_data_loader,validate_data_loader,model_folder=’PretrainModel/‘+model_folder,optimizer=optimizer,lr=lr,start_epoch=start,end_epoch=end_epoch,ckpt_step=ckpt_step,RESUME=resume)
File “/root/autodl-tmp/HIF-tool/HIFtool-main/fusion_mode.py”, line 77, in Supervisedfusion
output_HRHSI = model(LRHSI.cuda(), HRMSI.cuda())
File “/root/autodl-tmp/HIF-tool/HIFtool-main/Networks/CaFormer/net.py”, line 387, in forward
x = self.shallow_feat(r_0)
RuntimeError: Given groups=1, weight of size [64, 3, 3, 3], expected input[2, 128, 128, 128] to have 3 channels, but got 128 channels instead
我们略去一些系统包的报错,得到的提示如上,主要是三个部分的报错:
- Network_training_RS.py的第76行,调用fusion函数
- fusion_mode.py的第77行
- CaFormer的文件的net.py的第387行,显示卷积的通道数的大小出现了问题。
- 我们有一个提示,是在打印training后出现的报错
由training代码的报错,我们寻找调用fusion模块的传入的参数
bestepoch = Fusion(model,training_data_loader,validate_data_loader,model_folder=’PretrainModel/‘+model_folder,optimizer=optimizer,lr=lr,start_epoch=start,end_epoch=end_epoch,ckpt_step=ckpt_step,RESUME=resume)
维度错误是这一个代码的固有的bug,在长时间的调试无果以后,我们采用万能的print大法,进行对于代码的拆解。
通过print大法,我们首先得到了chikusei数据集的尺寸:
📌 原始GT(hrhsi)维度: torch.Size([2, 128, 128, 128])
📌 原始LRHSI(lrhsi)维度: torch.Size([2, 128, 4, 4])
📌 原始HRMSI(hrmsi)维度: torch.Size([2, 4, 128, 128])
第一个代表的时batch_size
目前报错的核心是以下这一行代码:
1 | self.shallow_feat = nn.Conv2d(in_c, n_feat, 3, 1, 1, bias=True) |
经过AI的辅助,我们把问题确认下来,是caformer在创建时,错误的进行了in_C的传参,我们梳理一遍报错的逻辑:
network_training_rs.py的76行:
1 | Fusion(model,training_data_loader,validate_data_loader,model_folder='PretrainModel/'+model_folder,optimizer=optimizer,lr=lr,start_epoch=start,end_epoch=end_epoch,ckpt_step=ckpt_step,RESUME=resume) |
调用第10行
1 | Fusion = ModeSelection(case) |
network/init.py函数中第11行,初始化caformer
1 | model = CaFormer(sf=opt.sf,in_c=opt.msi_channel, n_feat=opt.n_feat, nums_stages=num_iterations - 1,n_depth=opt.n_depth).to(device) |
经过我们的尝试,最后发现问题竟然是,传参的时候,in_c应该是hsi_channel,是的没错,这个bug让我干了一个星期,后续bug大体上完成了修复
9:47分,train到了第400个epoch
大致从第一天的早十一点,到了第二天的下午五点的样子,数据集还是相比来说很大的。
chikusei数据集的尺寸:
📌 原始GT(hrhsi)维度: torch.Size([2, 128, 128, 128])
📌 原始LRHSI(lrhsi)维度: torch.Size([2, 128, 4, 4])
📌 原始HRMSI(hrmsi)维度: torch.Size([2, 4, 128, 128])
xiongan数据集的尺寸:第一个是代表batch_size
📌 原始GT(hrhsi)维度: torch.Size([2, 93, 128, 128])
📌 原始LRHSI(lrhsi)维度: torch.Size([2, 93, 4, 4])
📌 原始HRMSI(hrmsi)维度: torch.Size([2, 4, 128, 128])
4和128中间相差的就是–sf参数,二者的做除法以后,需要是2的N次方
2026年3月3日
在复现和对代码的探索中,我发现了不少的问题,以下是论文中,复现时,论文中使用的数据集:
- Chikusei和Xiong’an数据集:选择左上角512×512像素的图像块作为测试图像,其余图像用于网络训练
- CAVE和Harvard数据集:随机选择20%的图像用于测试,剩余80%用于训练
- WorldView-2数据集:使用Wald协议生成训练样本,共创建2048对200×200×1的PAN图像块和50×50×4的LSR-MSI图像块
而在loader.py函数中,我们看到了很多的其他的数据集的class定义
- WDCM
- chikusei
- Pavia
- xiongan
- QB
一点点的吐槽
合着都不一样我训练个蛋。虽然有一丝丝的QB和WorldView-2数据集能够通用的可能性,但我们还是想要试一试,至于CAVE这样一个在论文中得到了很大笔墨的数据集,竟然没有它的接口!必须差评,必须差评!
我们通过梳理过往的一些数据,检查我们训练的结果与论文中的标称值:
论文的结果:
1 | +-----+-----+-----+-----+-----+-----+ |
我们的结果:(xiongan的eval还没有完全的跑通)
1 | +-----+-----+-----+-----+-----+-----+ |
我不知道是不是我跑的有一些问题,比如那个eval函数,我决定还是依靠原有的逻辑,尝试跑通一次eval函数
总结与综合
chikusei复现、训练结果


chikusei数据集并没有那么达,所以我们选择训练2000个epoch,我们的实验平台如下:
- autodl云端训练
- 4090显卡,显存24G,120G内存
我们实际占用的算力资源分配如下: - 约14GB显存,epoch_size=2,4就爆显存(24G)了
- 峰值约30GB内存,主要出现在数据加载阶段,运行后内存几乎没有发生改变
- GPU算力使用60%-80%
- CPU使用双核,利用率不高

但是,就很离谱,我们可以看到,1000个epoch的时候的PSNR的结果似乎还是最好的。随着训练的提升和lr的步长减小,PSNR的变化幅度几乎没有什么,而且在1000-2000的epoch的训练,似乎还使得模型进入了一个非常尴尬的局部优解。
最终,我们训练2000个epoch所用时间大约为1天左右
xiongan复现、训练结果


有了上一次的经验,这一次我们对于单个epoch比较大的训练集xiongan,我们决定训练500个epoch,实验平台和硬件情况和上一个在整体上十分的类似,蛋由于数据集比较大,我们最终的训练时间大约30个小时训练完了500个epoch
但是两个模型的结果都和论文的数据有了不少的误差
论文的结果:
1 | +-----+-----+-----+-----+-----+-----+ |
我们的结果:(xiongan的eval还没有完全的跑通)
1 | +-----+-----+-----+-----+-----+-----+ |
代码中的问题
首先我真的很想吐槽,msi和hsi字母一改,简直不像人事,class caformer的__init__函数的传参错误,但是最后报错根本没有报错和那一行有关,AI绞尽脑汁似乎是没有发现问题,最后还是祭出了祖传的print大法层层print锁定的问题,所以我们在接触一些新的方法的时候不能够忘记一些普通的方法,比如说去print
代码的结构主要如下所示:
1 | Network_training_RS.py |
论文中使用的数据集:
- Chikusei和Xiong’an数据集
- CAVE和Harvard数据集
- WorldView-2数据集
实际上在loader函数中提供的接口: - WDCM
- chikusei
- Pavia
- xiongan
- QB
所以我们目前只训练了,chikusei和xiongan,客官请看dataloader_tool中的:__init__.py函数
1 | from .loader import WDCMDataset, ChikuseiDataset, XionganDataset, PaviaDataset |
似乎这一个代码库就没有想让我们正常的用和复现的意思,连CAVE都没有import,更别说使用的Harvard数据集
但有一说一,除去chikusei和xiongan我们找到的数据集有:
- CAVE
- pavia
- QB
- world-view2
一些公开的高光谱数据集:
高光谱_多光谱_全色数据集以及光谱响应函数_harvard高光谱数据集-CSDN博客
可以,按你这个项目当前代码,我给你一个“可输入数据集 + 尺寸 + 结构”的完整结论。
1. 通过 Dataloader_tool 包直接可导入的类型
来自 init.py:
WDCMDatasetChikuseiDatasetXionganDatasetPaviaDatasetLarge_dataset(在loader_L.py)
另外,loader.py 里还定义了 QBDataset,但没在 __init__.py 导出(见 loader.py)。
2. loader.py 四类主数据集(RS)的输入格式与尺寸
统一输出结构(__getitem__)都是字典:
hrhsi: 高分高光谱,(C_hsi, H, W)lrhsi: 低分高光谱,(C_hsi, h, w)hrmsi: 高分多光谱,(C_msi, H, W)
参考 loader.py。
A) WDCMDataset
定义见 loader.py
- 输入文件:
.mat,键名S(见 loader.py) - 光谱通道:HSI=191,MSI=13(见 loader.py)
- 内部裁剪原图:
[:1280, :288] - 默认
patch_h=3, patch_w=3, ratio=32 - 默认单样本(train/eval):
hrhsi:(191, 96, 96)lrhsi:(191, 3, 3)hrmsi:(13, 96, 96)
- 默认 train patch 数:174(但
__len__返回 348,做了*2,见 loader.py)
B) ChikuseiDataset
定义见 loader.py
- 输入文件:
chikusei.mat(HDF5),键名chikusei,原始是(C,H,W),代码转成(H,W,C)(见 loader.py) - 你仓库实测:
(128,2335,2517)-> 转置后(2335,2517,128) - 光谱通道:HSI=128,MSI=4
- 默认
patch_h=4, patch_w=4, ratio=32 - 默认单样本(train/eval):
hrhsi:(128, 128, 128)lrhsi:(128, 4, 4)hrmsi:(4, 128, 128)
- 默认 train patch 数:361(
__len__=361)
C) PaviaDataset
定义见 loader.py
- 输入文件:
.mat,键名GT(见 loader.py) - 光谱通道:HSI=93,MSI=4
- 默认
patch_h=3, patch_w=3, ratio=32 - 默认单样本(train/eval):
hrhsi:(93, 96, 96)lrhsi:(93, 3, 3)hrmsi:(4, 96, 96)
- 默认 train patch 数:100(但
__len__返回 200,见 loader.py)
D) XionganDataset
定义见 loader.py
- 输入文件:
.npy(见 loader.py) - 光谱通道:HSI=93,MSI=4
- 训练/验证内部先裁剪为:
[:3744, :1568] - 你仓库实测:
xiongantrain.npy:(3750,1580,93)(可用于 train/eval)xiongantest.npy:(512,512,93)(不适配当前type='test'的固定裁剪)
- 默认
patch_h=4, patch_w=4, ratio=32 - 默认单样本(train/eval):
hrhsi:(93, 128, 128)lrhsi:(93, 4, 4)hrmsi:(4, 128, 128)
- 默认 train patch 数:1568(
__len__=1568)
3. QBDataset(在 loader.py 里,但未导出)
定义见 loader.py
- 读 PanCollection 风格
lms/ms/pan(mat或h5) - 通道设置:HSI=4,MSI=1
- 常用于 QB pansharpening 数据
- 注意:如果你写
from Dataloader_tool import QBDataset,当前__init__.py下默认拿不到它。
4. Large_dataset(VL 任务)
导出于 init.py,定义在 loader_L.py
- 支持
CAVE/HARVARD(见 loader_L.py) - 返回结构是元组
(HR, LR, RGB),不是字典 - CAVE 在项目里是
512x512x31(你仓库实测)
5. 结构层面的关键结论(很重要)
- 这套
loader.py的 RS 数据集本质是“先退化生成lrhsi/hrmsi,再切 patch”。 - 训练和评估很多时候不是用独立 test 文件,而是从同一大图按固定区域切(比如 Xiongan 的
eval)。 XionganDataset(type='test')有固定坐标裁剪[1750:2262,650:1162](见 loader.py),所以512x512的xiongantest.npy会报空数组错误。- 不同数据集归一化策略不一致(WDCM 是按通道 min-max,Chikusei/Pavia 是全图除 max,Xiongan 默认不归一化),这会影响指标可比性。
对于 ChikuseiDataset,完整流程是:
- 从
chikusei.mat读出原始高光谱图chikusei - 从
C,H,W转成H,W,C - 对一块区域做复制修补
- 做全局归一化,得到标准化的
HRHSI - 用高斯模糊 + 按
ratio抽样,生成LRHSI - 用光谱响应函数
R做线性投影,生成HRMSI - 在 train/eval/test 模式下按不同规则切区域、切 patch
- 在
__getitem__里转成 PyTorch 需要的(C,H,W)格式 - 最终返回:
- 目标
HRHSI - 输入
HRMSI - 输入
LRHSI
- 目标
这是一篇高光谱与多光谱融合的论文,我们以之为例,进行深挖,掌握对于代码的理解。以下是论文的两个主要的结构图: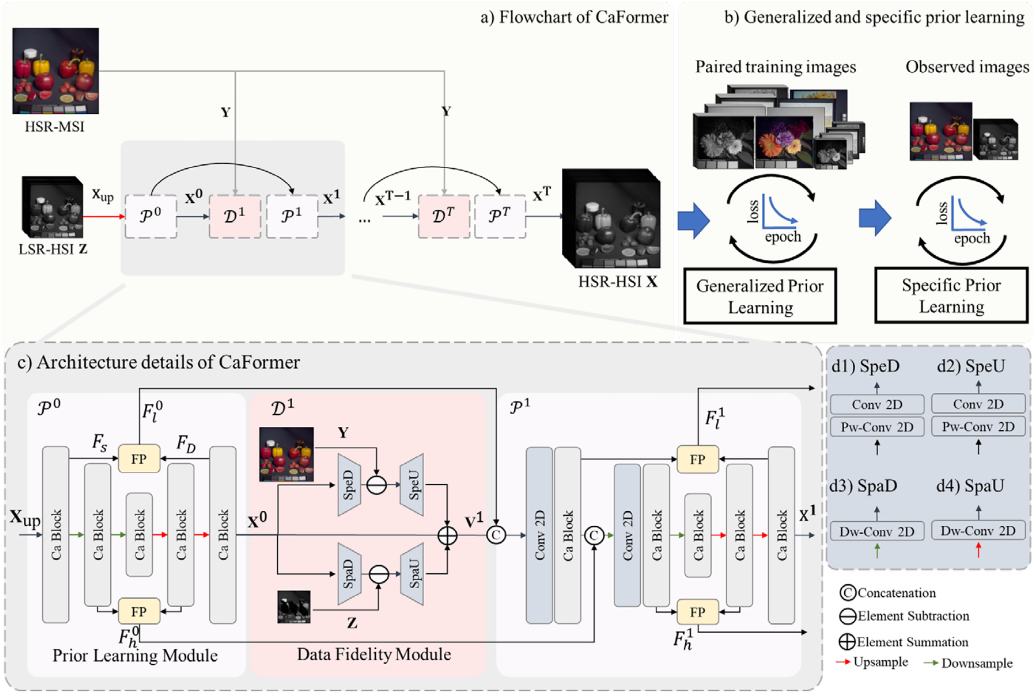
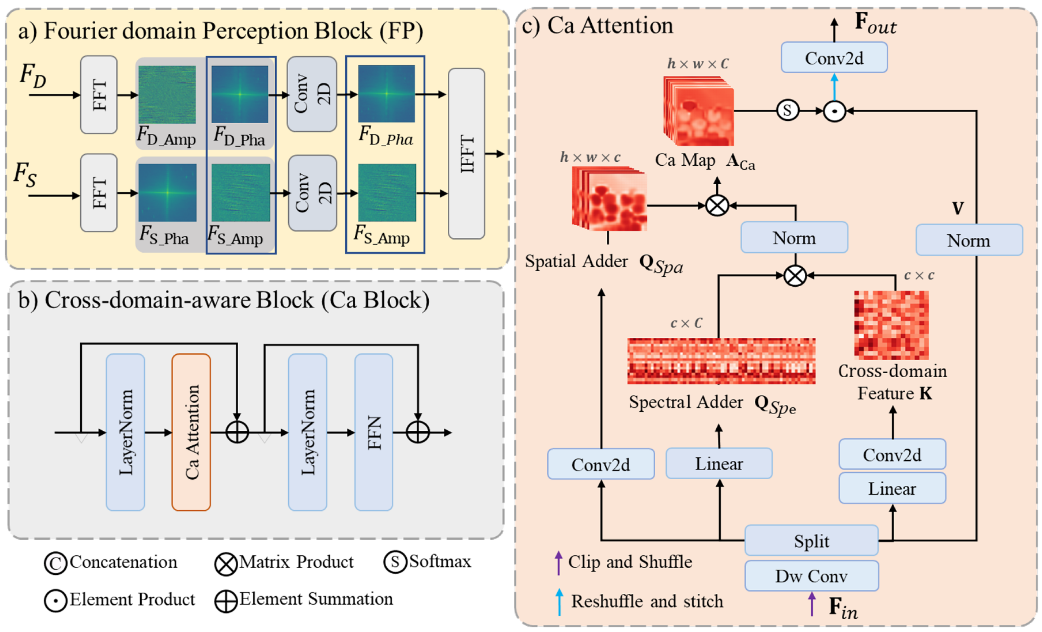
读代码
定义
一个标准的网络的文件,前面都是用来定义很多的工具。比如说import相应的库,或者说要调用的函数的索引。一些要使用的函数工具,在这个代码中,前置了:
1 | def to_3d(x): |
这种就是一个标准的工具定义,下面还有一个是对于归一化曾的定义,在此略去不详细讲述
功能块
代码中有着一个又一个的分类,这些基本最后都是一个一个的class,我们一个一个展开。
1 | class FeedForward(nn.Module): |
首先的init初始化,我们可以看到经过了三个卷积层,分别是dim通道数,映射到2hidden_features个通道数,然后每个通道接受各个通道的输入进行卷积,最后定义的那个是把hidden_features个通道映射回dim个通道的操作
通过下面的forward前馈,我们看到原始的卷积层分为了x1x2两个部分,然后进行门控,x1进行gelu的激活,然后对于x2进行门控,对于低激活的信息,在最后的处理后展现出被抑制的效果