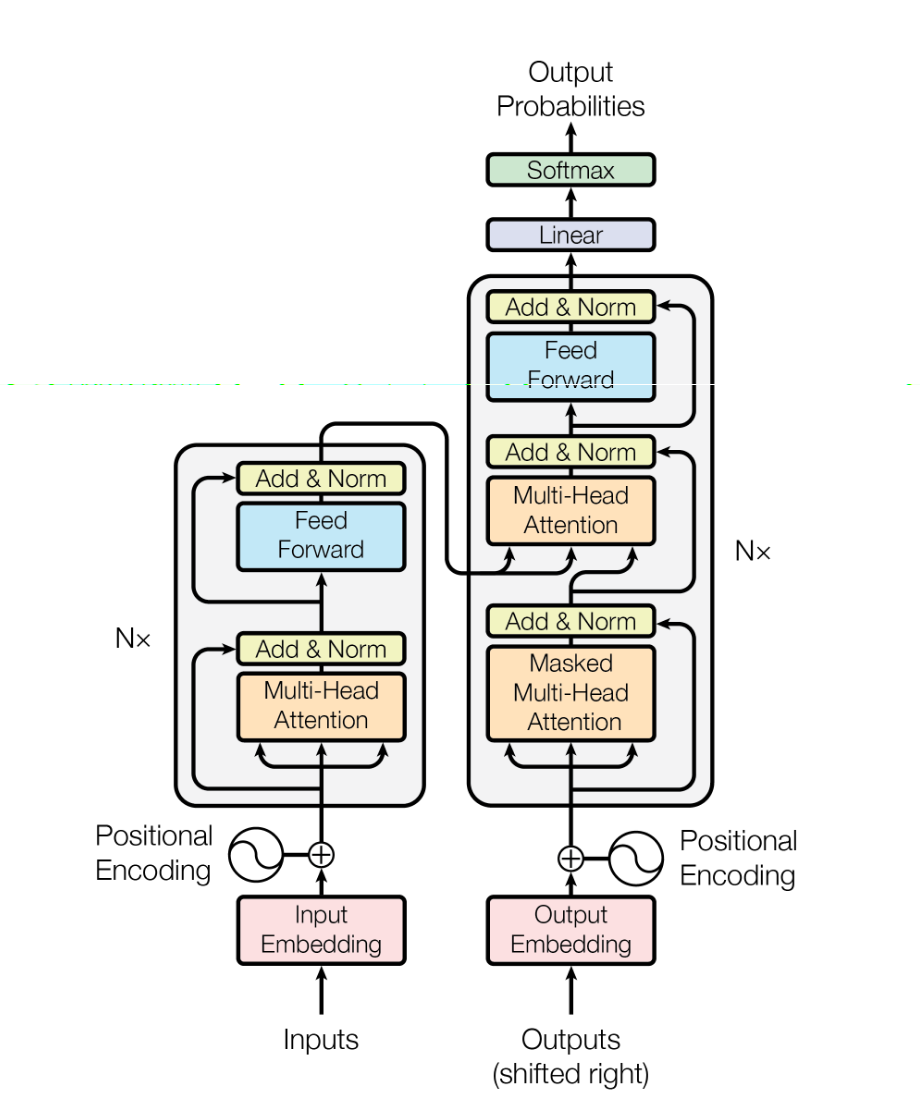
9:读经典,attention is all you need
这一篇论文,在2017年以一个标题党的姿态产生,但是当时对它提起注意的人似乎没有那么多。但就是这么一个work,在如今的各种领域之内攻城略地,几乎没有很多人注意到,这开启的是一个AI的新时代,不断攻城略地,从机器翻译到整个NLP,然后在现在,几乎打遍了CV。现在,没有用到transformer的地方已经很少了。
In this work we propose the Transformer, a model architecture eschewing(故意避免) recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
我们完全抛弃RNN,提出transformer。CNN这个网络,长距离建模非常的难。Transformer 是第一个完全基于自注意力的转导模型。
之前已有很一些工作使用CNN并行计算输入输出的隐藏表达来减少序列化计算,但是2个任意位置之间的计算量随着位置之间距离的增加而增加,有的是线性关系,有的是对数关系,而Transformer进一步把计算量降低到常数关系,以降低有效分辨率为代价(因注意力权重的平均),MHA抵消了这种负面效果。
2026年3月24日
怀着一种对于transformer的无限的敬畏,我想,去真真切切的了解,这一个transformer,这样一种惊世骇俗的存在。
最好的致敬,是重走来时路。我想,通过我的手搓,能够完成这样一件伟大的作品,并且对于它的前世今生的一些情况,进行一些体悟与感知。
的确,在现在,用vibe coding去实现一个transformer的难度,几乎无限持平于从git上面把它给拷贝到电脑上,然后点击run。但是这并不能让我对于这样一个。从渗透NLP-CV的壁垒到如今各行各业的方方面面,transformer在书写着一个又一个的神话的架构,有着更多的了解。
所以我想走进她,不用AI,all by myself,去手搓这一段代码。但由于本人的代码水平的确有限,所以我选择去follow一个blog:(8 封私信 / 80 条消息) 从0手搓Transformer(代码拆解篇) - 知乎去跟随着这一个博主,完整的coding这一个framework。有可能我不能完整的完成每一个链条的coding,考虑到我的学习目的而不是工程经验,我肯会通过手打的方式,抄一些代码。
transformer模型拆解
来自于博主的参考资料:
代码拆解
Transformer 模型代码拆解
- Positional Encoding(位置编码)
- Multi‑Head Attention(多头注意力)
- Feed Forward Network(前馈网络)
- Transformer Encoder Layer(Transformer 编码器层)
- Transformer Encoder(Transformer 编码器)
- Transformer Decoder Layer(Transformer 解码器层)
- Transformer Decoder(Transformer 解码器)
- Transformer Model(Transformer 模型)
- mask function(掩码函数)
- Example usage(示例用法)
文件的结构
1 | . |
PositionEncoding
位置编码,这是一个很有意思的地方。原论文的截图:
由于模型很难读取位置信息,我们需要对它的位置进行编码。位置编码的每一个维度对应一个正弦波。