7:论文笔记-Frustratingly Simple Few-Shot Object Detection
由于我的挑战杯是小样本检测,所以我想通过这样一篇文章,对于这个网络和这一个东西有着一个基础的了解
读论文
abstract
Detecting rare objects from a few examples is an emerging problem. Prior works show metalearning is a promising approach. But, finetuning techniques have drawn scant attention.
从少量样本中完成特征的检测是一个比较难的任务,在这个的研究方法中,元学习得到了广泛的关注,而微调没有引起很多的关注。
We find that fine-tuning only the last layer of existing detectors on rare classes is crucial to the few-shot object detection task.
只是对于现有的探测器的最后一层进行微调,感觉有点意思。
conclusion
We proposed a simple two-stage fine-tuning approach for few-shot object detection. Our method outperformed the previous meta-learning methods by a large margin on the current benchmarks.
提出的是一个双阶段的微调方法
introduction
The ability to generalize from only a few examples (so called few-shot learning) has become a key area of interest in the machine learning community.
所以我们工作的核心是对于少数的例子进行推广,通过个别的信息去发现新的特征。
我们采用了如图1所示的两阶段训练方案进行微调。我们首先在数据丰富的基类上训练整个物体探测器,如Faster R-CNN(任 等,2015),然后仅在包含基础类和新类的小型平衡训练集上微调探测器的最后几层,同时冻结模型的其他参数。在微调阶段,我们引入了受Gidaris & Komodakis(2018)启发的实例级特征归一化;Qi 等人(2018);Chen 等(2019)。
Also, the previous evaluations only report the detection accuracy on the novel classes, and fail to evaluate knowledge retention on the base classes.
这是intro提到的一个点,还有一个问题是我们在关注新类是否发现的时候,我们还要去注意旧类是否得到了充分的检测。
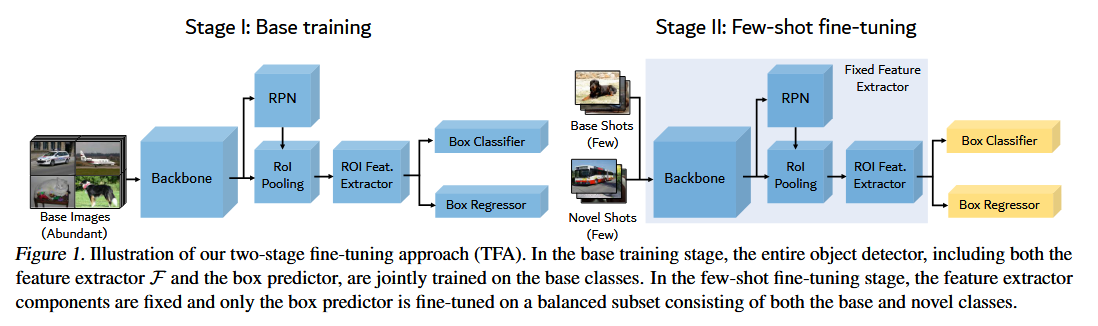
这里面展示的就是网络的训练过程,对于大样本数据先训练所有的权重,然后对于小样本的数据把前面的几层全都冻结,只把最后的一个box层的数据进行微调,相当于是用少量的数据集进行微调,微调最后的权重。
这里面的一个潜台词是什么呢,我觉得就是最后的这样一个box层才是对于这个网络影响最大的一个部分。
- backbone:主干网络,比如resnet,完成全局的特征提取,一般是深度展开的卷积网络
- RPN(Region Proposal Network,区域生成网络),像yolo一样分框框,然后二分类判断前景后景。实现初步的微调,即目标位置的确定
- RoI Pooling(Region of Interest Pooling),实现的是,裁剪的不同区域最后变成同一个维度的信息,就是池化
- ROI Feat. Extractor,全连接或者卷积,后面就进入最终的分类和回归。
最后的两个,是微调/不微调的两个:
- Box Classifier,边界框分类器,完成多分类任务,判断具体是哪一个类别。
- Box Regressor,边界框的回归器,最后使选中的框框更加接近于真实的边界。
Algorithms for Few-Shot Object Detection
Two-stage fine-tuning approach
这里面的主干网络使用的是faster R-CNN
We assign randomly initialized weights to the box prediction networks for the novel classes and fine-tune only the box classification and regression networks, namely the last layers of the detection model, while keeping the entire feature extractor F fixed.
新颖的类别,直接对最后的盒预测网络赋予随机的,微调检测模型的最后几层,保持整个特征提取器的F不变。
Cosine similarity for box classifier,在第二阶段考虑使用基于余弦相似度的分类器
Meta-learning based approaches
元学习方法
Both the meta-learning approaches and our approach have a two-stage training scheme. However, we find that the episodic learning used in meta-learning approaches can be very memory inefficient as the number of classes in the supporting set increases. Our fine-tuning method only finetunes the last layers of the network with a normal batch training scheme, which is much more memory efficient.
这里讲了元学习的一个很大的问题,就是当目标增加比较多的时候,元学习的效率可能非常低。
实现细节。我们以Faster R-CNN(任等,2015)为基础,Resnet-101(He等,2016)作为骨干,并以特征金字塔网络(Lin等,2017)为骨干。所有模型均使用SGD训练,最小批次为16,动量为0.9,权重衰减为0.0001。基础训练期间学习率为0.02,少量精细调校时为0.001。欲了解更多详情
一文读懂Faster RCNN(大白话,超详细解析)-CSDN博客faster rcnn的一篇文章