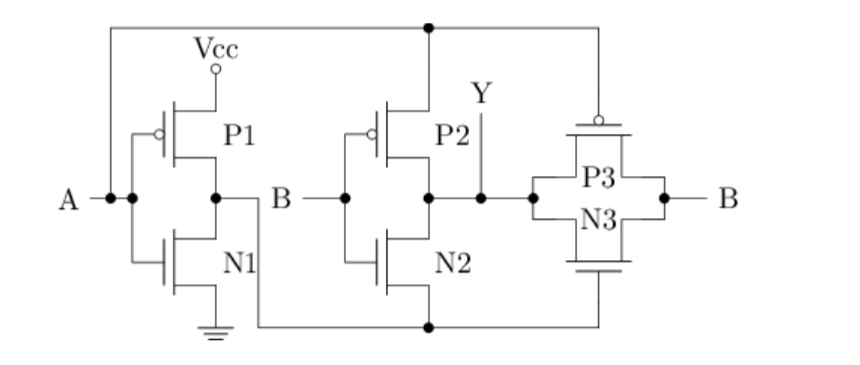
F5 支持数列求和的简单处理器
要求:
在此之前, 我们需要再次明确需要实现的指令集sISA的细节. 和上一小节相比, 此处还约定了一些寄存器的位宽:
- PC位宽为4位, 初值为
0 - GPR有4个, 位宽均为8位
- 支持如下3条指令
1 | 7 6 5 4 3 2 1 0 |
最多执行16条指令,不含benr0
现有情况,支持8位int,最大数为256
我们将这个用数字电路实现的sISA指令集的CPU称为sCPU. 要实现sCPU, 我们需要用数字电路实现sISA中的每一个概念. 为了简单起见, 我们先从最简单的li指令开始考虑, 也即, 先实现一个只支持li指令的sCPU
只有一套指令的sCPU
我们先从ISA的状态机模型回顾执行一条li指令的具体过程. 事实上, 无论是执行什么指令, 其步骤都是类似的, 有一个叫”指令周期”(instruction cycle)的概念专门描述这些步骤:
- 取指(fetch): 根据当前PC, 在存储器中找到一条指令
- 译码(decode): 看这条指令具体是什么指令, 操作数是哪些
- 以
li指令为例, 操作数需要看立即数是多少, 需要写入哪个目的寄存器
- 以
- 执行(execute): 对操作数进行处理, 必要时更新指定的目的寄存器
- 更新PC: 让PC指向下一条指令
因此, 我们的目标就是用数字电路实现上述过程的每一个步骤.听起来很有意思。
取指
存储器和寄存器都可以存储信息,但存储器还支持寻址(addressing),也即,存储器中的内容按顺序进行排布,给出一个地址,存储器可以读出该地址对应的内容。
从功能上划分, 存储器可以分别只读存储器(Read-Only Memory, ROM) 和随机访问存储器(Random Access Memory, RAM), 前者不支持写入, 而后者支持. 对于sISA来说, 因为3条指令都不会访问存储器, 只有取指操作需要从存储器中读出指令, 因此这里可以采用ROM.
一个2x3的ROM的结构如下图所示. 左上方的译码器又称”地址译码器”. 和地址译码器输出相连的导线称为”字线”(word line), 每条字线对应一个存储字. 和或门输出相连的导线称为”位线”(bit line), 每条位线对应存储字的一位.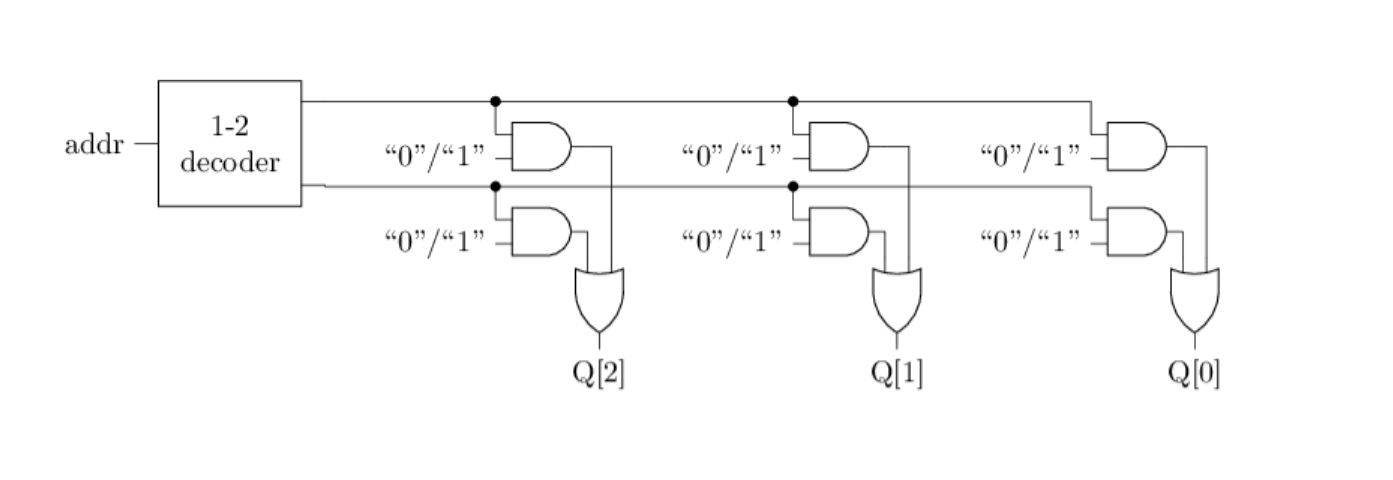
给定addr地址后,通过编码器的作用,最后输出独热编码,最后只有一路会被点亮,经过与门的过滤作用后,其它门的信息被过滤为0,在最后一个门电路处,不会得到输出,只有被选中的存储字,最后会得到输出。
在事实上,图中的电路构成了一个3位的2选1选择器,因此ROM的操作,同时也是在N个选择器中,最后选择一个作为最终数据进行读取。
通过多路选择器实现一个ROM, 并在其中存放数列求和的指令序列, 然后通过PC寄存器取出指令. 你需要根据你的理解来确定ROM的规格.
我们决定采用8位的数字寄存器,8位指令的ROM。其中左上角是一个累加的PC。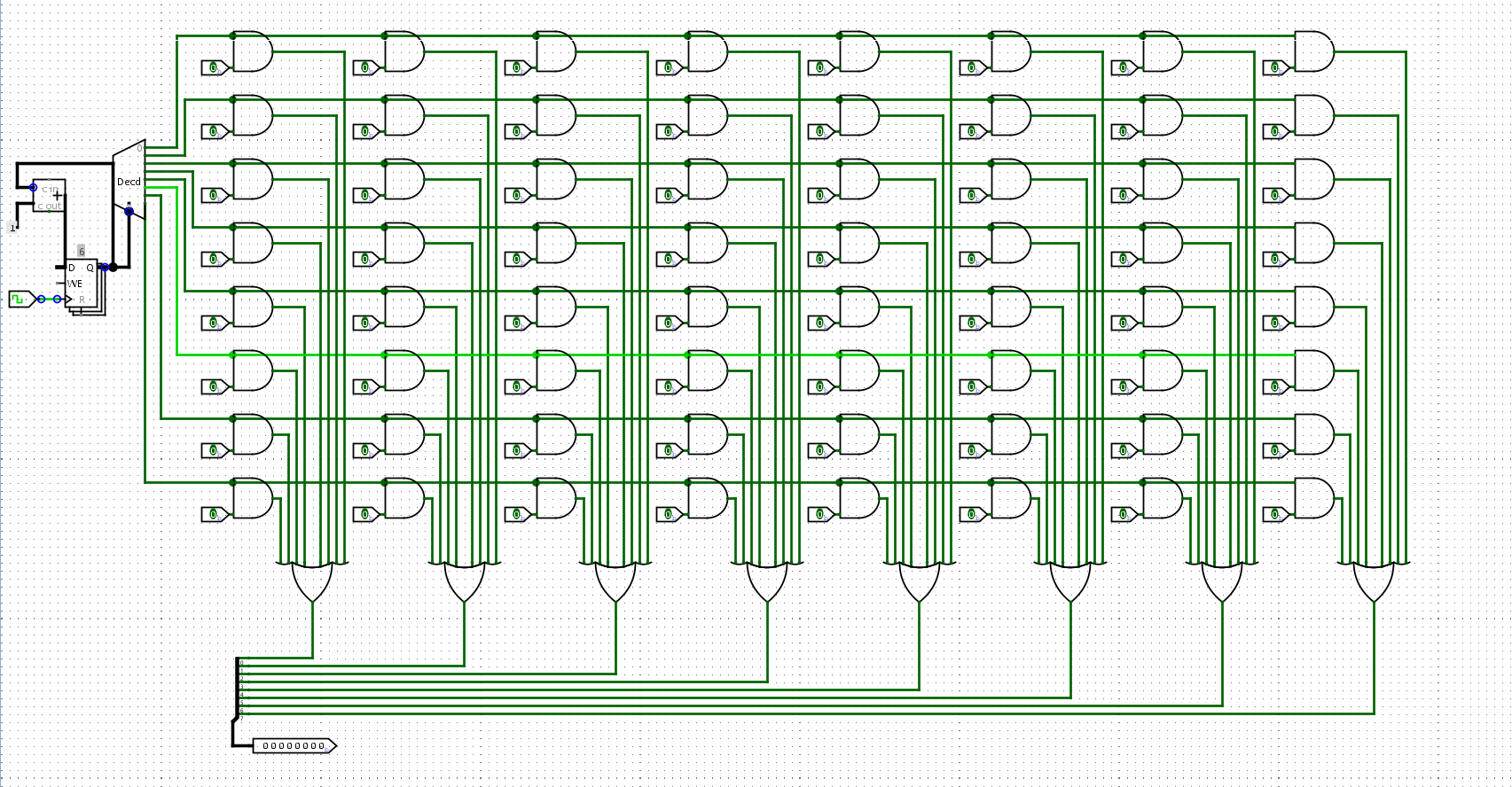
译码
由于电路中存在的是二进制表示的指令,所以我们要在二进制层面,对其进行译码。目前而言,我们要实现的只是一条li指令,所以我们只用默认为是1条指令,然后对于操作数的译码,我们只用抽取其中某些位进行运算。
li的指令的功能是将立即数imm写入rd寄存器,一次我们需要考虑如何实现ISA的GPR。GPR包含着指令寻址和数据写入功能,不难发现这实际上是一个RAM
我们加入一个写呢能信号,用于标注是否该进行写入,所以,我们可以总结一个RAM的工作状态如下:
- 当使能信号为1,addr输入位的地方,可以接受信号的寻址。
- 不难发现,这是一个但端口的RAM,即为在同一时刻只能够通过一个地址访问其中的一个存储子,称为单端口RAM
- 同时,译码器也可以加入,最后实现一个addr和encoder可以同时控制写入信号和读取信号
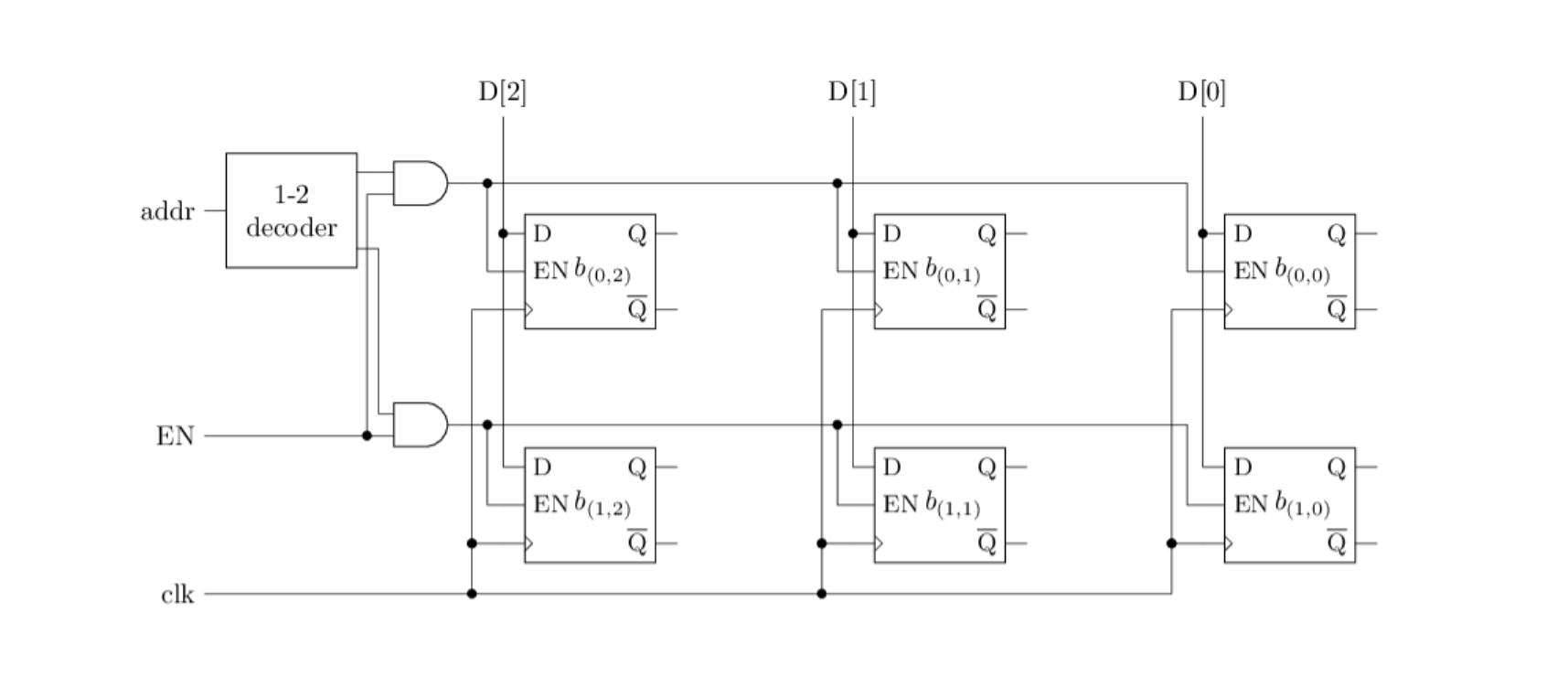
在寄存器的基础上搭建一个RAM, 从而实现GPR的写入功能. 你需要根据你的理解来确定RAM的规格.
根据要求,我们的GPR有4个寄存器,每一个寄存器存储八位的数据。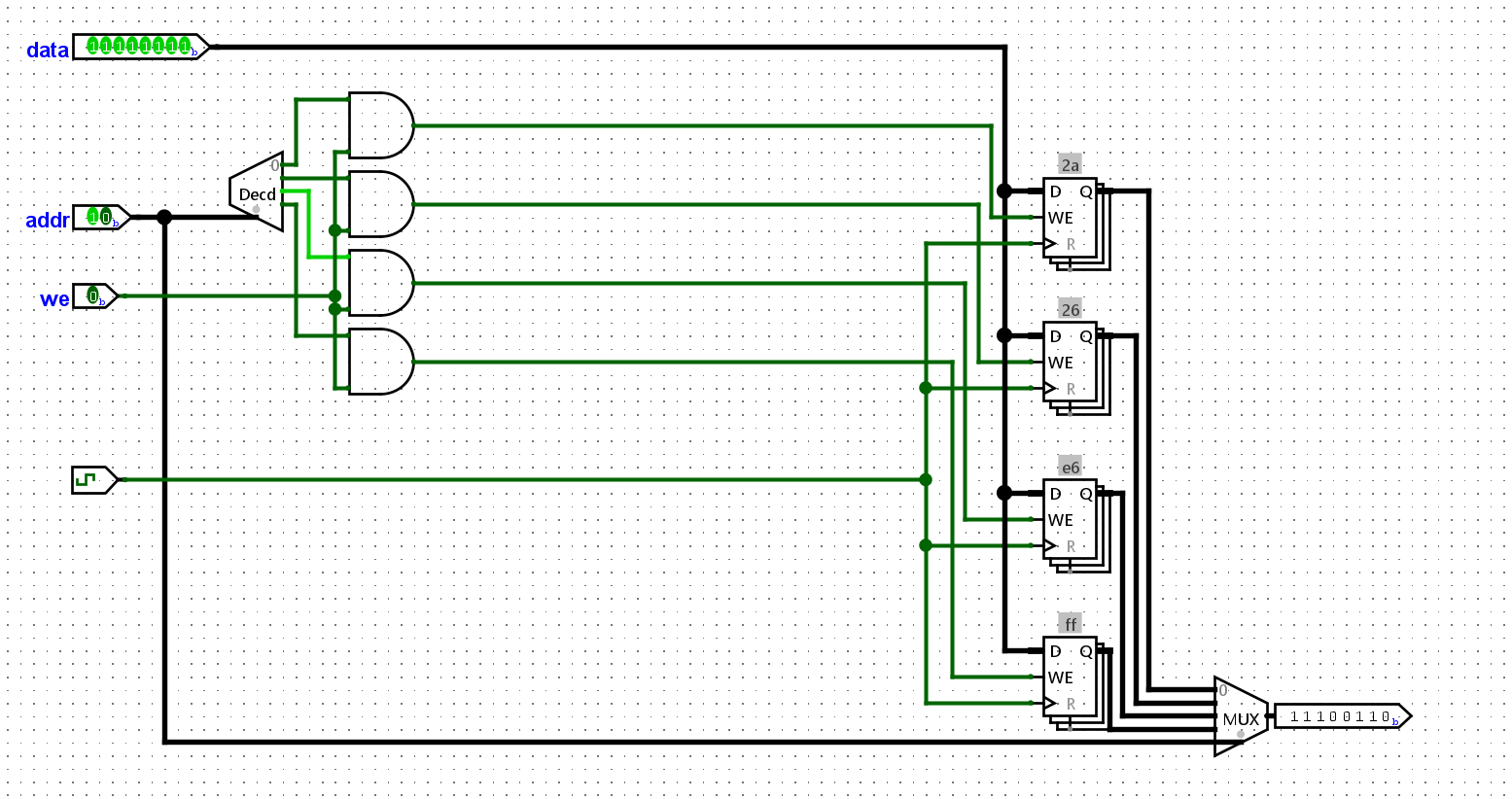
更新PC
PC寄存器+1,至少在没有benr0的情况下的确是这个样子的
实现仅仅支持li指令的sCPU
根据上文, 用数字电路实现li的指令周期涉及的各个部件, 并将它们连接起来. 实现后, 尝试让sCPU执行数列求和程序中的前几条li指令, 并观察电路中GPR的状态是否与ISA的状态一致.
我们来分析支持li组件的CPU需要的几个元素:
- 一个PC
- 一个ROM进行存储,以及提前写好的数据
- 对ROM传递的数据的拆分与分线
我们可以暂时不管指令的12位,对于34位我们传递进入RAM的addr中,然后进行补0到8位,实现的结果如下所示: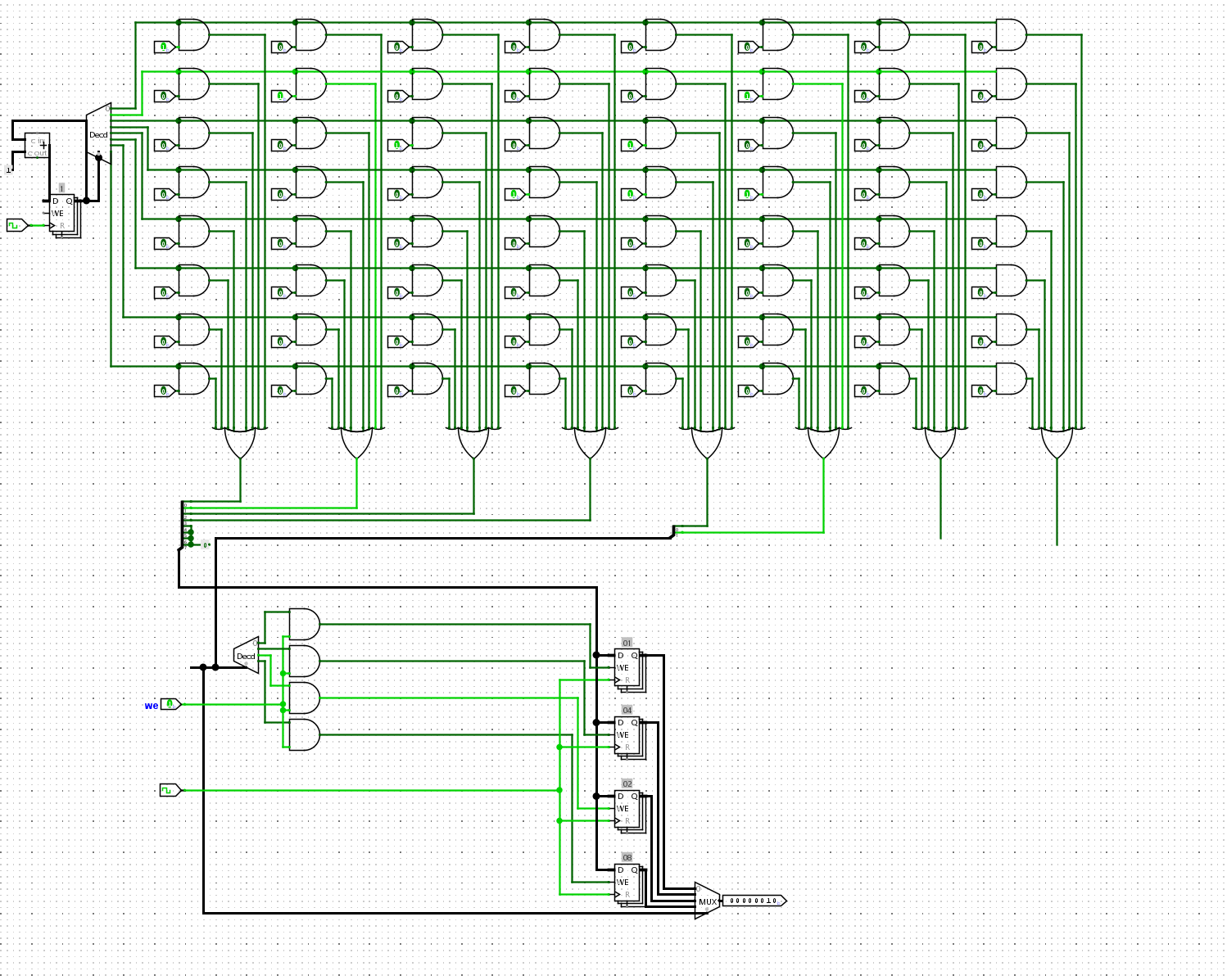
虽然我们最终似乎实现了一个支持单一指令的sCPU,但是我们也感觉到,我们手搓的CPU在调试的过程中似乎没有那么的容易,我们在划分位数和最后的寻址环节,是发生了一些错误的,我们需要对它进行一些改进,使之符合使用的规范。
实现完整的sCPU
接下来考虑如何实现add指令,对于译码,我们对于add的opcode字段,如果是00,则是add指令,如果是10,则是li指令。最适合的电路就是译码器!
考虑到opcode只有两位,我们可以使用一个2-4的译码器,它输出的独热码可以指示当前的指令属于何种指令
添加add指令:
根据上文, 在sCPU中添加add指令. 实现后, 尝试让sCPU继续执行数列求和程序中的几条add指令, 并观察电路中GPR的状态是否与ISA的状态一致.
我们需要能够封装住GPR。为了便宜我们的设计,我们需要对于GPR进行封装,我们需要完成的指令有:
- add指令,需要至少能够同时读取两个数据,载入一个数据,需要写使能,写地址,写数据
- li指令,需要写地址,写数据,写使能
所以我们需要的端口有:
- 第一个读取端口:raddr1,rdata1
- 第二个读取端口:raddr2,rdata2
- 写端口:waddr wdata wen clk
共有八个端口,我们需要对其进行封装
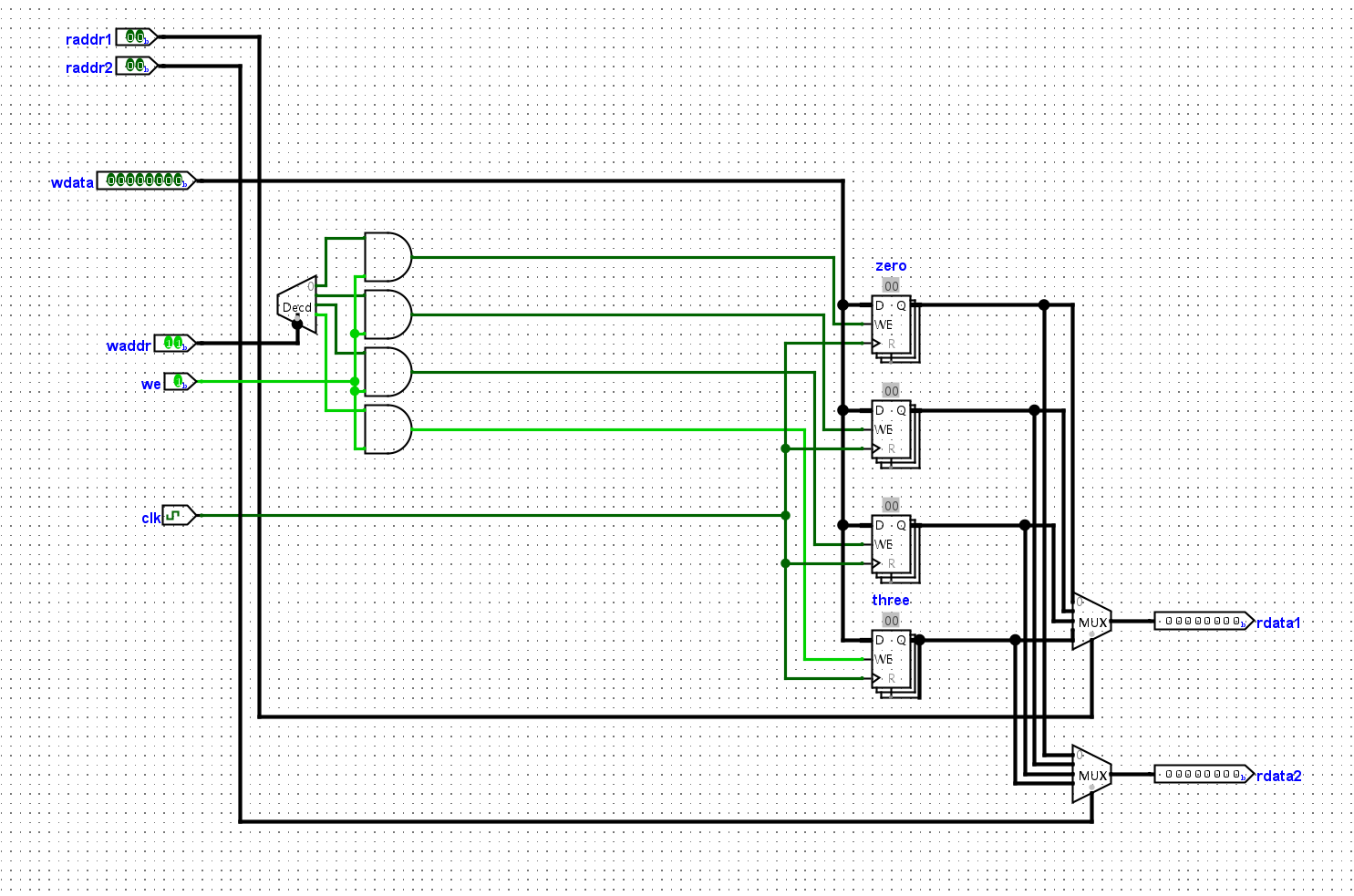
好的,我们再来分析
- li信号,需要提供写使能信号,写数据,和数据本身
- add信号
- 需要raddr1和raddr2输入
- 需要读取rdata1和rdata2,做加法,写入到wdata
- 根据wdata和waddr,更新寄存器
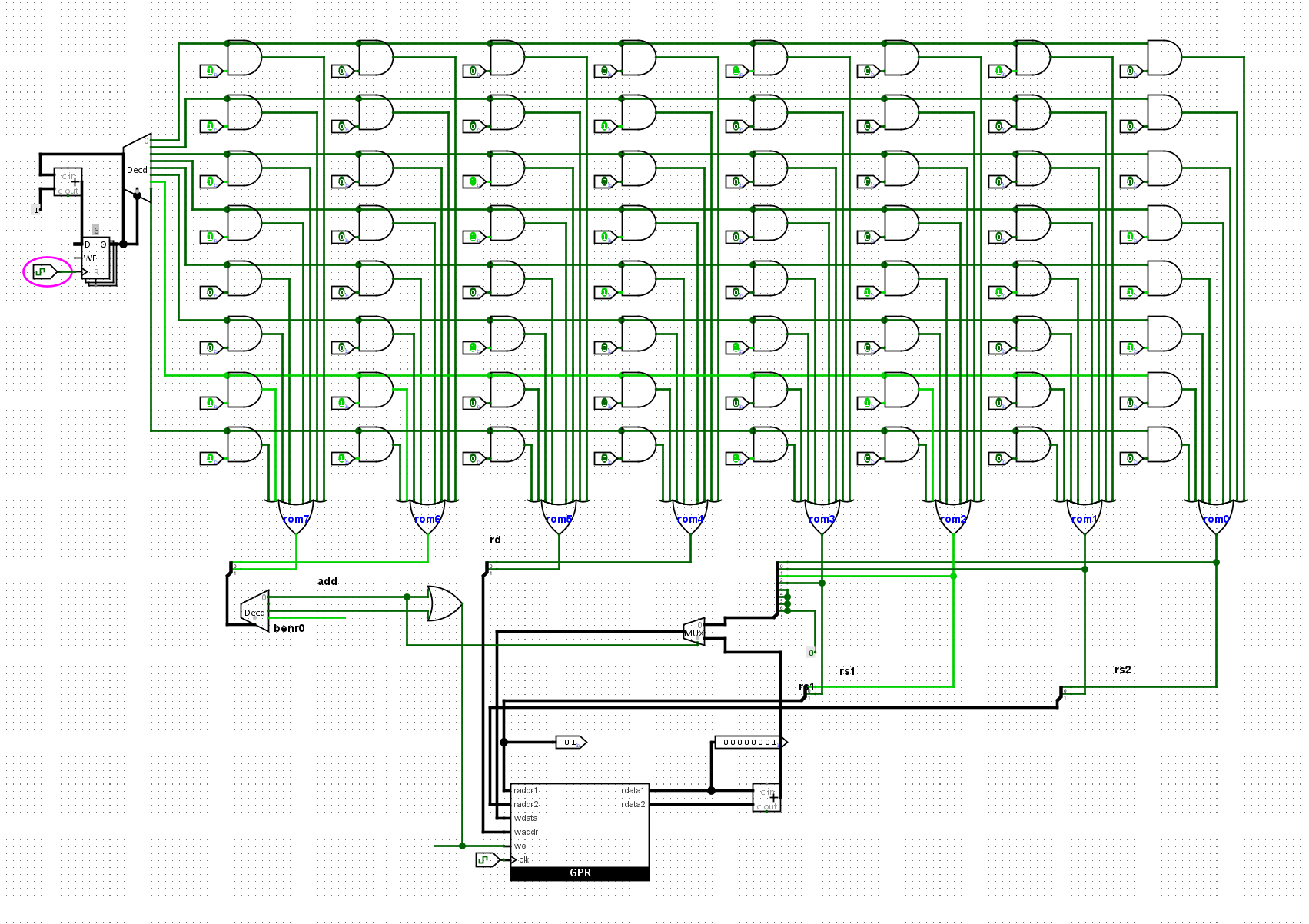
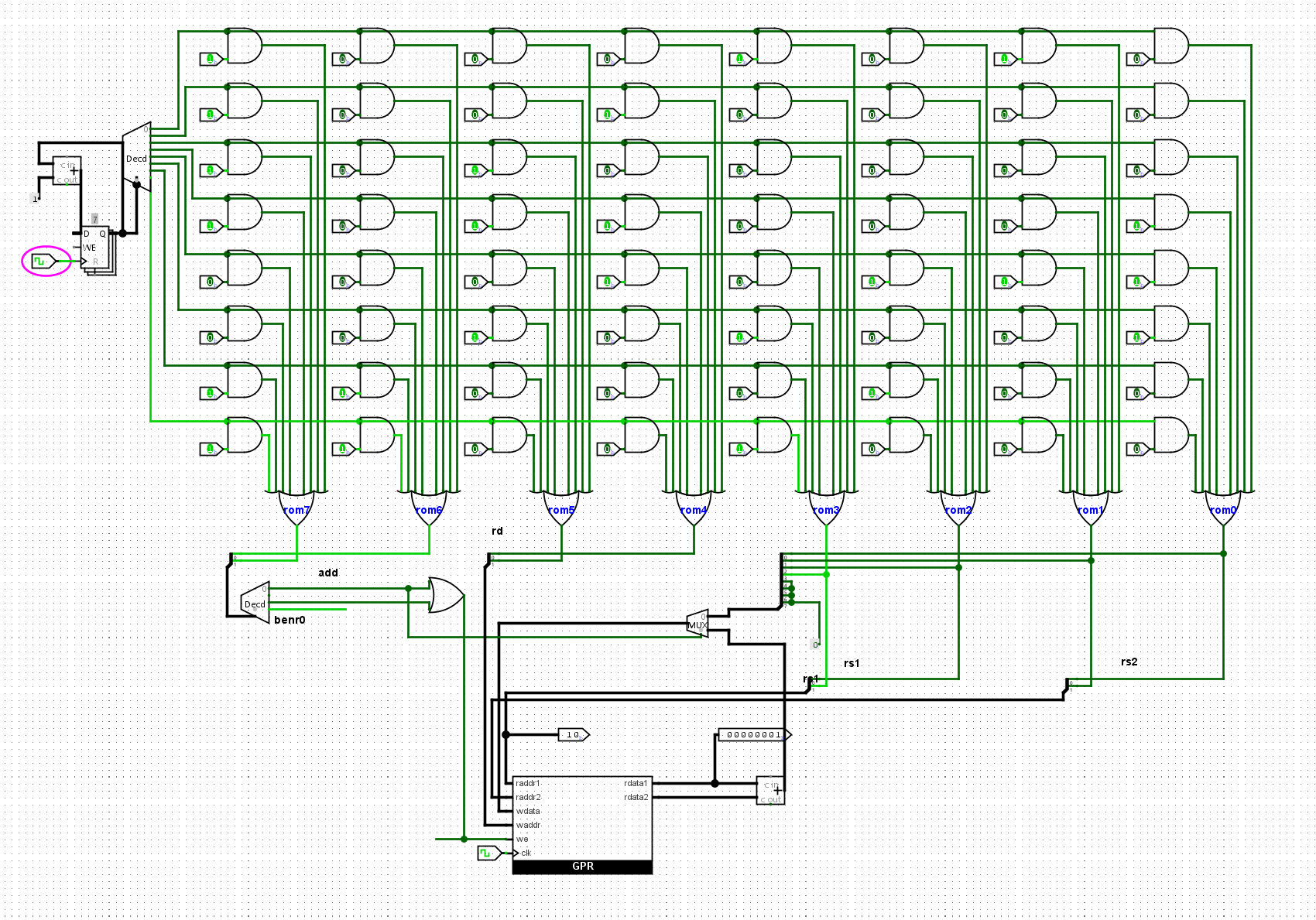
添加bner0指令
根据上文, 在sCPU中添加
bner0指令. 实现后, 尝试让sCPU执行完整的数列求和程序, 如果你的实现正确, 你应该能看到PC最终为7, 且在某GPR中存放求和结果55.
最后是bner0指令. 为了识别bner0指令, 我们可以复用指令译码器的功能. 至于操作数, 除了指令中的rs2和addr, 还有一个隐含的R[0]. 由于bner0指令中rs2字段的位置和add指令中rs2字段的位置一样, 因此可以复用add指令中读出rs2寄存器的逻辑. 但bner0还需要读出R[0], 因此可以把0作为GPR的raddr1端口的输入. 不过这个端口已经被add指令的rs1占用, 但也同样可以通过多路选择器的解决问题.
读出源操作数后, bner0指令需要比较两数是否相等, 这可以通过比较器来实现. 若比较结果不相等, 需要将PC更新为addr字段. 换句话说, 只有当前指令为bner0指令, 且比较结果不相等, 才将PC更新为addr字段, 其余情况应将PC更新为PC加1. 同样地, 我们可以借助多路选择器对PC寄存器的输入端进行选择.
最后, bner0指令不会写入GPR, 因此需要将GPR的wen置为无效.
所以我们对于benr0指令进行设计,内容需要包括
- PC的输入端,多路选择器
- 比较器,结果为01判断,然后默认的读取字符,一个是0,一个等待输入。
- wen使能端不开放,可以直接不给,wen默认为没有
- 多路选择器的使能端,唯一由11通路决定,只有在11通路有效时,才可以进行使用。
其01位,代表要比较的地址,2-5位代表PC写入的addr的地址,6-7位代表11指令,而对于地址位的控制读取,我们仍然需要一个多路选择器,用于选择可以通过的信号。我们看到,在之前的指令中,01位时通过raddr2的,所以我们只需要在23位,加一个多路选择器和raddr1即可完成这个逻辑。
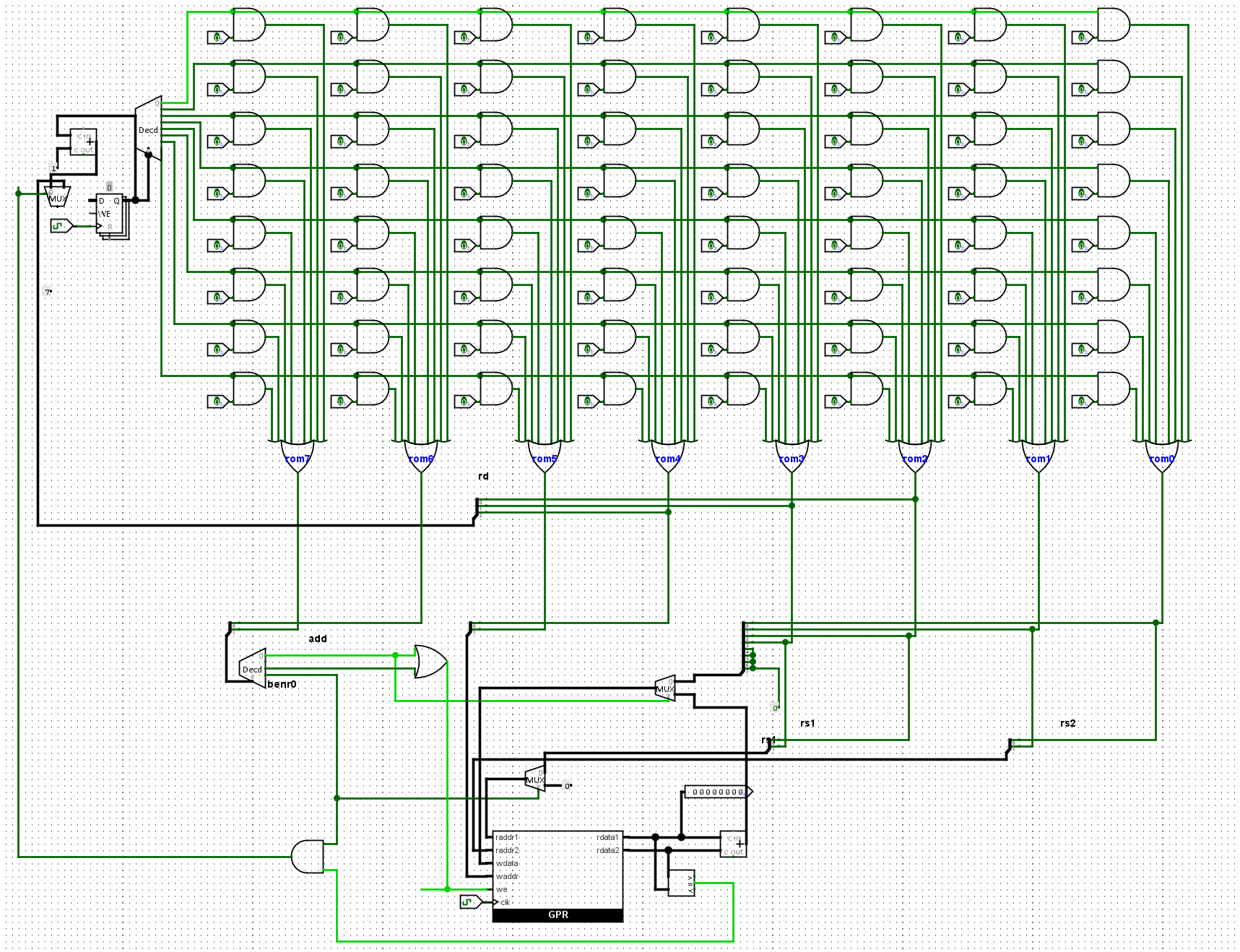
我们在这里加入了benr0指令,运用到两个多路选择器,一个比较器,和一个与门,在与是否等于的信号进行与门运算后,作为最后PC更新的控制信号
我们增加几个输出端口,对这个结构进行一个调试.我们加入了data数据的实时的去,以及PC段的值的显示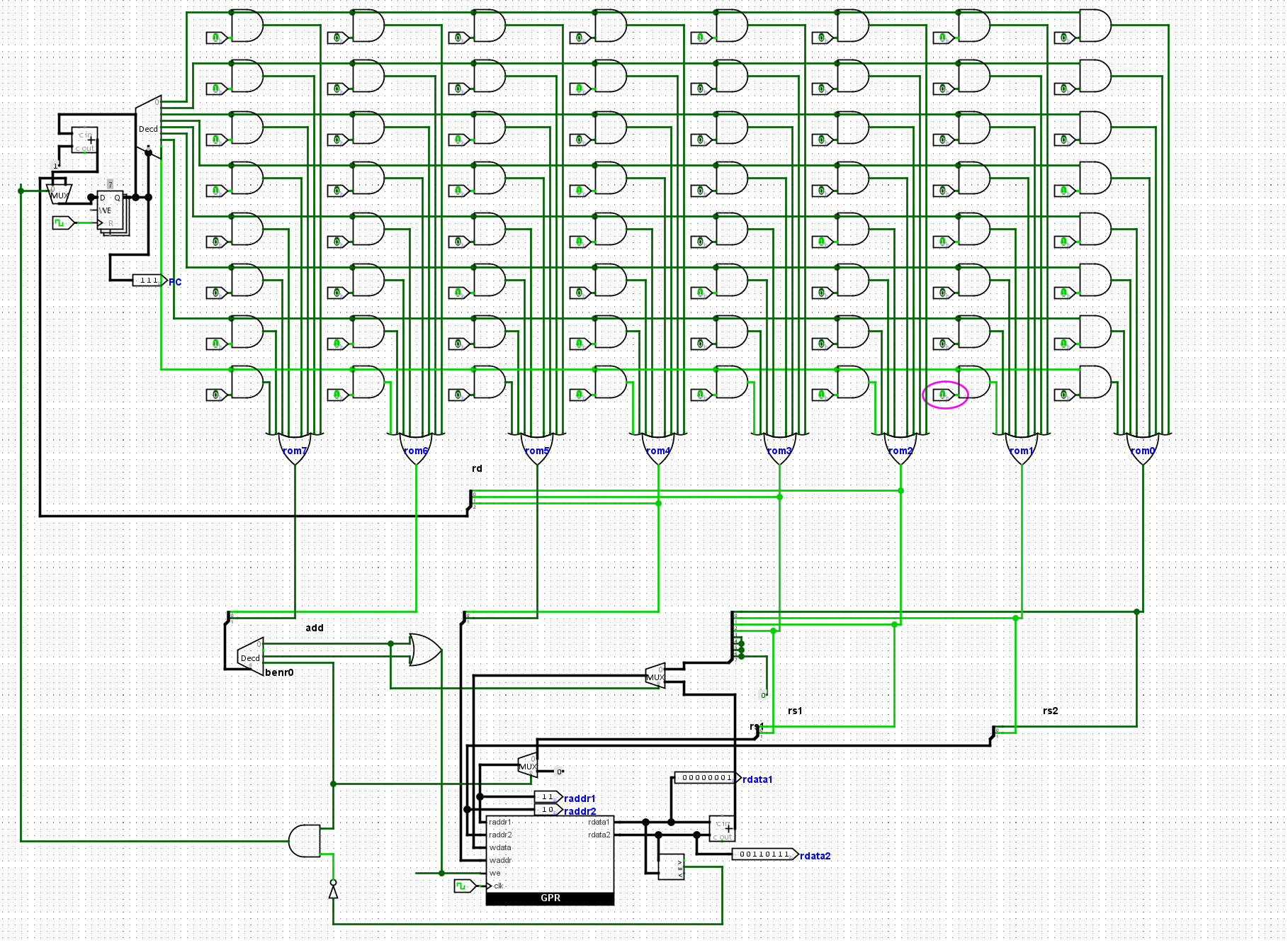
我们的CPU可以成功实现1-10的累加,输出结果为rdata2所示,值为55,和实际的结果一致。
最后的benr0指令非常有意思,执行完了以后就让这个命令卡在这一个命令了,方便我们进行调试,查看当前的寄存器的实时值。PC最终的结果为7
和数列求和电路进行对比
在学习数字电路时, 有一道必做题要求你通过寄存器和加法器, 计算出
1+2+...+10的结果. 现在你用sCPU完成了同样的计算, 尝试对比两个方案各有什么优点和缺点.
优点:指令的可变性,可以通过外部的指令输入,灵活的进行运算,而之前学的寄存器和加法器,属于i硬编码,功能单一。使用了循环的思想,有效利用。可拓展性非常牛逼。
缺点:硬件使用,而且多个指令之间的选择与兼容,的确非常非常的复杂
计算10以内的奇数的和
实际上并没有很难,我们只需要把上述的rdata3改成2,r0改成1就可以顺利地完成这个命题。对于存储程序,其输入的编码,唯一决定输出的结果
添加out指令
实际上我们可以寻找一个小bug,因为其中的01位是固定的输出位,所以我们只用把rdata2给接入输出就欧克了,实在还有对out有要求,比如说没有out指令时不进行输出的话,我们可以把rdata2和00做一个选择器,这样的结果就是。可以在出现out指令的时候完成输出。数码管就不复制过来了,整体还是非常的复杂的。
能够实现一条让10个数相加的指令吗
显然不行。
从程序角度:指令的长度会很长,8位完全不够
从ISA的角度,ISA会有繁琐的冗余
从CPU的角度,加法器由于只有两个输入,做加法,还有一个cin,1和1和1总体还是在两位以内,不然就会出现两位进位,三位进位的极端情况,严重影响到了计算的效率
小结
自此,我们顺利的完成了F5,道阻且长,行则将至