6:论文笔记 Equalization Loss v2 A New Gradient Balance Approach for Long-tailed Object Detection
这是一个 EQLv2 (Equalization Loss v2) 目标检测项目,基于MMDetection v2框架开发并进行了深度定制。该项目主要解决长尾分布(long-tail distribution)下的目标检测问题——即数据集中大量类别具有极少的样本,导致模型在这些稀有类别上的表现极差。考虑到ddl马上到来,我们对于代码进行先行的处理。https://github.com/tztztztztz/eqlv2。
这个项目代码目前支持COCO、LVIS、OpenImages等多个长尾分布的主流的数据集。
首先我们对于项目的结构进行分析如下:
1 | mmdetection-eql/ |
这是AI生产的一个目录,我们结合这个目录,展开下一步的工作。
对于训练,我们的函数调用逻辑是:
调用链路:dist_train.sh → tools/train.py → mmdet/apis/train.py → 加载模型配置(mmdet/models/detectors/mask_rcnn.py) → 设置损失函数(mmdet/models/roi_heads/bbox_heads/losses.py中注册的EQL/EQLv2) → 训练循环
读论文
这个文章解决的是一个什么问题呢,就是
a realistic scenario, we are confronted with a more complex situation that the obtained objects show an extreme imbalance in different categories.
数据集极端不均衡下的不平衡,主要是两个方面:
- 尾类数据量和标注太少,模型不足以学习到
- 模型会倾向于打类的数据,学习到大类的特征
这篇论文提到的SOTA是解耦方法,两阶段检测与建模后微调的方法。
对于之前提供的EQL均衡损耗方法,这是一种端到端的重新加权损失函数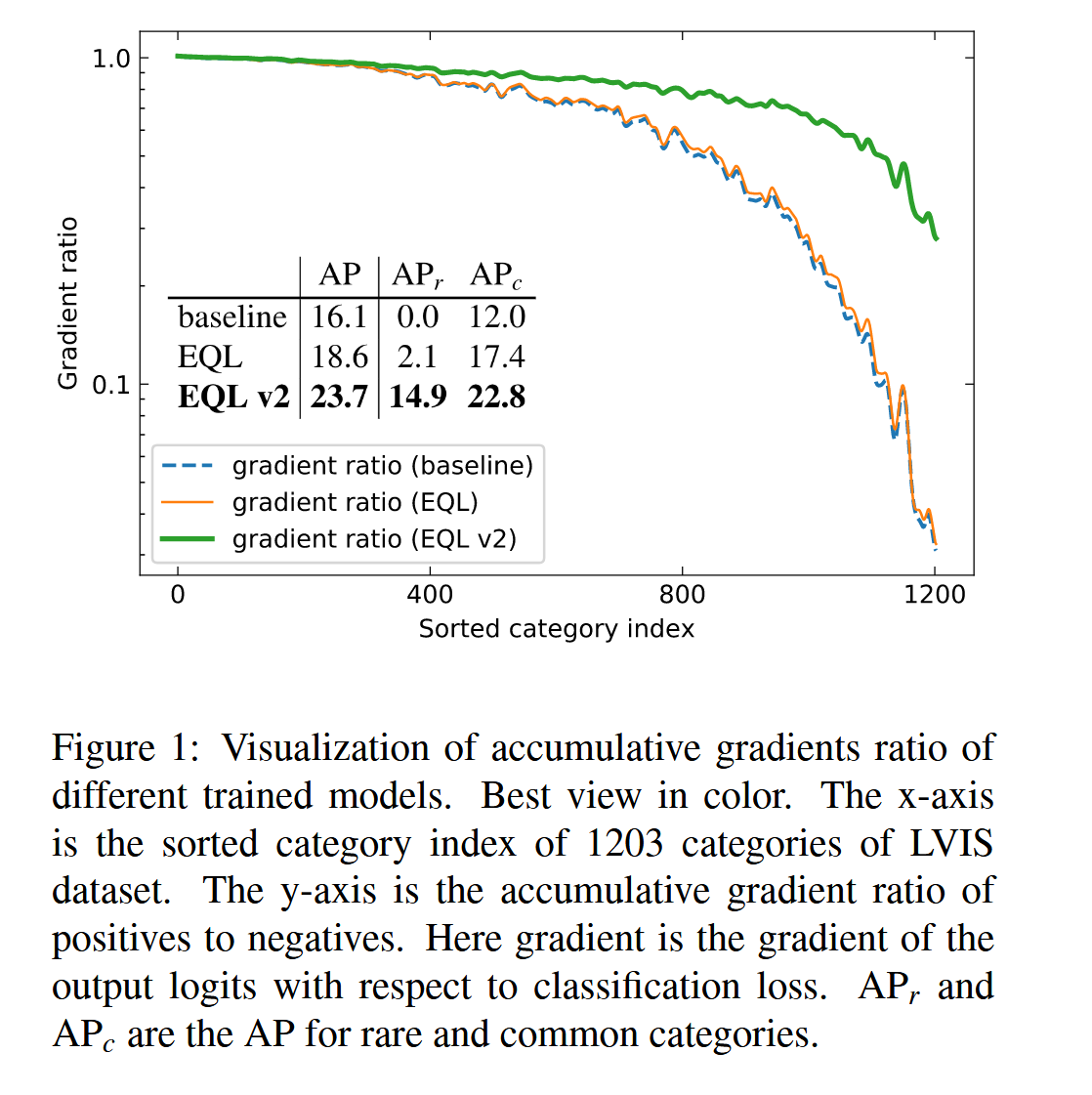
对于头类别,比值接近1,这意味着正梯度和负梯度的幅度相近;对于尾部类别,梯度接近0,这意味着正梯度被负梯度所覆盖。而我们可以看到,在梯度比这个衡量的因素里,EQL只是增加了一点点,没有很太大的变化,但是v2却增加了非常非常多。