
13:再看 YOLOv4
我读这样一篇论文的目的已经有了变化。下面讲一下我对于这一篇 paper 的理解。
我们赛题的核心是:不均衡小样本、光学遥感、陆上时敏目标检测识别。对于基础算力环境,其实并没有那么大的要求,因为类似 3090 级别的算力平台已经能够解决非常多的问题。所以我们更多需要学习的是 YOLOv4 中一个个具体模块的设计思路。
一、Selection of Architecture
CSPDarknet53 在检测任务上效果更加优秀,而 CSPResNext50 在分类任务上表现更加优异。
遥感图像中的目标通常很小,背景复杂。如果 backbone 太轻,容易漏检;但如果 backbone 太重,又难以满足大幅面图像的推理时间要求。
论文里面讲了这样一句话:
A reference model which is optimal for classification is not always optimal for a detector. In contrast to the classifier, the detector requires the following.
分类和检测之间存在矛盾,二者并不完全一致。与分类不同,检测任务需要满足如下要求:
- 更高的输入分辨率:前面的网络不能压缩太狠;
- 更多层:这一点我还没有完全理解;
- 更多参数:意味着更强的目标信息提取能力。
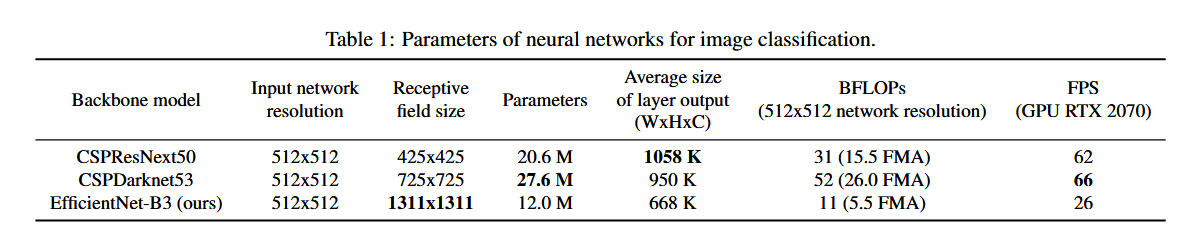
几个需要关注的指标:
- 感受野;
- 参数量;
- 输出层尺寸。
CSPDarknet53 包含 29 个卷积层、3 个 (3 \times 3) 卷积,感受野为 (725 \times 725),参数量为 27.6M。这一理论依据,加上论文中的众多实验,表明 CSPDarknet53 是两者中更适合作为检测器 backbone 的模型。
因此,要重视感受野这个概念的影响。

感受野的意义可以理解为:
- 当感受野大小等于目标物体尺寸时,网络能够“看到”完整目标;
- 当感受野大小等于输入图像尺寸时,网络能够“看到”目标周围的上下文信息;
- 当感受野大小超过输入图像尺寸时,会增加图像像素点与最终激活特征之间的连接数量。
1.1 SPP Block
SPP 块可以显著增加感受野,分离最重要的上下文特征,并且不会明显降低运行速度。
YOLOv4 中的 SPP 不是传统分类网络里的固定长度池化,而是在特征图上使用不同尺度的 max-pooling,例如:
- (1 \times 1)
- (5 \times 5)
- (9 \times 9)
- (13 \times 13)
然后将这些特征拼接起来。
它的作用是扩大感受野,让网络看到更大范围的上下文。
1.2 PANet
PANet 用作不同主干网络层级与不同检测器层级之间的参数聚合方法,而不是 YOLOv3 中使用的 FPN。
PANet 是小目标检测的关键模块之一。遥感小目标往往只占很少像素:
- 高层特征:语义强,但空间细节少;
- 低层特征:空间细节多,但语义弱。
PANet 的价值就是把二者结合起来。
1.3 YOLOv4 最终结构
YOLOv4 最终网络结构可以概括为:
1 | CSPDarknet53 + SPP/PAN Neck + YOLOv3 Multi-scale Detection Head + DIoU-NMS / NMS |
综上,这就是 YOLOv4 的整体结构。
二、论文方法理解
这篇文章给我的感觉是:作者做了大量的消融实验,对于每个部分都进行了层层优化,也告诉我们每一部分的衡量指标是什么。
核心内容集中在论文的 2.2、2.3 和 3.3 三个部分。
三、YOLOv4 损失函数详解
3.1 YOLOv4 损失函数总体构成
YOLOv4 的损失函数由三个核心部分组成:
[
\text{Loss} = L_{box} + L_{conf} + L_{cls}
]
| 损失项 | 符号 | 作用 | YOLOv4 采用方案 |
|---|---|---|---|
| 边界框回归损失 | (L_{box}) | 衡量预测框与真实框的位置偏差 | CIoU Loss |
| 置信度损失 | (L_{conf}) | 判断网格单元内是否存在目标 | BCE Loss |
| 分类损失 | (L_{cls}) | 判断目标所属类别 | BCE Loss |
3.2 从 MSE 到 IoU 的演进
3.2.1 MSE Loss
YOLOv3 及早期版本采用 MSE 作为边界框回归损失:
[
L_{MSE} = \frac{1}{N} \sum_{i=1}^{N} \left[ (x_i - x_i^{gt})^2 + (y_i - y_i^{gt})^2 + (w_i - w_i^{gt})^2 + (h_i - h_i^{gt})^2 \right]
]
3.2.2 IoU Loss
为解决 MSE 的缺陷,IoU Loss 被提出:

[
\text{IoU} = \frac{\left|B \cap B^{gt}\right|}{\left|B \cup B^{gt}\right|}
]
[
L_{IoU} = -\ln(\text{IoU})
]
或者:
[
L_{IoU} = 1 - \text{IoU}
]
其中,(B) 为预测框,(B^{gt}) 为真实框。
IoU Loss 的优点是:
- 将边界框回归转化为几何重叠度的优化,具有尺度不变性;
- 直接反映检测框与真实框的重合程度。
3.3 GIoU Loss
GIoU Loss 提出于 2019 CVPR,用于解决 IoU 在预测框与真实框不相交时失效的问题。
它的核心思想是引入最小外接矩形,即 Smallest Enclosing Box,记作 (C),作为惩罚项。

GIoU 的公式为:
[
\text{GIoU} = \text{IoU} - \frac{\left|C - \left(B \cup B^{gt}\right)\right|}{\left|C\right|}
]
[
L_{GIoU} = 1 - \text{GIoU}
]
其中,(C) 为能同时包含预测框 (B) 和真实框 (B^{gt}) 的最小矩形。
GIoU 的改进点是:
- 当两框不相交时,(\text{GIoU} \in [-1, 0)),仍然可以提供梯度;
- 通过外接矩形面积惩罚,引导预测框向真实框移动。
GIoU 的不足是:
- 当预测框完全包含在真实框内且大小相同时,GIoU 会退化为 IoU,无法区分相对位置关系。
3.4 DIoU Loss
DIoU Loss 提出于 2020 AAAI,在 GIoU 基础上进一步引入中心点距离惩罚。
它的核心思想是:同时优化重叠面积和中心点距离,从而加速收敛。

DIoU 的公式为:
[
\text{DIoU} = \text{IoU} - \frac{\rho^2(b, b^{gt})}{c^2}
]
[
L_{DIoU} = 1 - \text{DIoU}
]
其中:
- (b, b^{gt}):预测框与真实框的中心点坐标;
- (\rho(\cdot)):两点间的欧氏距离;
- (c):最小外接矩形 (C) 的对角线长度。
DIoU 的优势是:
- 不重叠时仍然能够提供梯度;
- 直接最小化两框中心距离,收敛速度优于 GIoU;
- 在水平和垂直方向上回归更快。
DIoU 的不足是:
- 没有考虑边界框的长宽比一致性,当中心点重合但长宽比不同时,无法进一步区分。
3.5 CIoU Loss
CIoU Loss 是 YOLOv4 最终采用的边界框回归损失。
它提出于 2020 AAAI,与 DIoU 来自同一篇论文。CIoU 在 DIoU 的基础上进一步增加了长宽比惩罚项。
CIoU 综合考虑边界框回归的三个几何要素:
- 重叠面积;
- 中心点距离;
- 长宽比一致性。
CIoU 的公式为:
[
\text{CIoU} = \text{IoU} - \frac{\rho^2(b, b^{gt})}{c^2} - \alpha v
]
[
L_{CIoU} = 1 - \text{CIoU}
]
其中:
[
v = \frac{4}{\pi^2} \left( \arctan\frac{w^{gt}}{h^{gt}} - \arctan\frac{w}{h} \right)^2
]
[
\alpha = \frac{v}{(1 - \text{IoU}) + v}
]
YOLOv4 选择 CIoU 的原因是:
- 实验表明,CIoU 在检测精度和收敛速度上均优于 IoU、GIoU 和 DIoU;
- 对多尺度目标,尤其是遥感影像中的小目标,具有更好的回归稳定性。
3.6 五种损失函数对比总结
| 损失函数 | 重叠面积 | 不相交处理 | 中心距离 | 长宽比 | 代表论文 |
|---|---|---|---|---|---|
| MSE | ❌ 独立参数 | ❌ 无梯度 | ❌ 无 | ❌ 无 | YOLOv3 早期 |
| IoU | ✅ | ❌ 梯度消失 | ❌ 无 | ❌ 无 | UnitBox, 2016 |
| GIoU | ✅ | ✅ 外接矩形惩罚 | ❌ 间接 | ❌ 无 | CVPR 2019 |
| DIoU | ✅ | ✅ | ✅ 直接惩罚 | ❌ 无 | AAAI 2020 |
| CIoU | ✅ | ✅ | ✅ | ✅ 角度差度量 | AAAI 2020 |
四、长尾分布目标检测损失函数调研
赛题的核心矛盾是:
召回率要求 (\geq 85%),但部分类别样本不到 10 张。
损失函数分配梯度失衡,传统模型严重“偏科”:头部类很准,尾部类几乎视而不见。
4.1 EQL v2
EQL v2 是分类损失的主力方案。
论文:Tan J. et al., CVPR 2021
4.1.1 核心发现
尾部类学不好的真正原因是:
正确分类的背景产生的负梯度,挤压了尾部类的特征空间。
4.1.2 解决思路:各管各的
设计一:把多分类拆成 (C) 个独立二分类任务,背景独立为第 (C+1) 类
训练时,标签为“背景”的样本不参与任何目标类的计算,仅参与背景类自己的“是背景 / 非背景”判断。
设计二:每类独立二分类
汽车、导弹车、飞机等类别各自进行独立的“是 / 否”判断,互不干扰。
但是,头部类目标仍然可能大量存在,因此长尾问题并没有被完全根治。
4.1.3 动态平衡梯度
EQL v2 会实时监控每类正负梯度比例 (r_c),并用 (r_{target}) 作为预设的目标梯度比例,动态调节正负梯度权重:
[
r_c = \frac{\sum \left|g_c^{+}\right|}{\sum \left|g_c^{-}\right|}
]
[
w_c^{+} = \min\left(1, \frac{r_{target}}{r_c}\right)
]
[
w_c^{-} = \min\left(1, \frac{r_c}{r_{target}}\right)
]
4.2 Focal Loss
Focal Loss 可以作为置信度损失的基线方案。
论文:Lin T.-Y. et al., ICCV 2017
4.2.1 核心思想
Focal Loss 的思路是在标准交叉熵损失的基础上新增一个系数因子,从而:
- 减弱对容易样本的学习;
- 加强对困难样本的学习;
- 提高模型的分类能力。
4.2.2 公式定义
[
FL(p_t) =
\begin{cases}
-\alpha (1-p_t)^\gamma \log(p_t), & y=1 \
-(1-\alpha) p_t^\gamma \log(1-p_t), & y=0
\end{cases}
]
其中:
- (p_t):模型对目标类的预测概率;
- (\gamma):用于调节模型对困难样本和简单样本的关注程度;
- 当预测概率 (p_t) 接近 1 时,即简单样本,((1-p_t)^\gamma) 会非常小,从而减少损失贡献;
- 当预测概率 (p_t) 接近 0 时,即困难样本,((1-p_t)^\gamma) 会变大,从而增加损失权重,使模型更加关注难分类样本。
4.3 Seesaw Loss
Seesaw Loss 可以作为分类损失的备选方案。
论文:Wang J. et al., CVPR 2021
4.3.1 核心思想
Seesaw Loss 通过两个互补因子来动态重平衡每个类的正负梯度。
在长尾数据中,头部类负梯度太大,会压住尾部类正梯度。Seesaw Loss 不改变整体优化方向,只动态调整梯度大小,让正梯度与负梯度恢复平衡,像跷跷板两端持平。
4.3.2 Mitigation Factor
Mitigation Factor 的作用是:
不让头部类在训练时疯狂压制尾部类,让尾部类的分类器权重不被压垮,从而能够正常学习。
计算方式如下:
[
\mathcal{M}_{ij} =
\begin{cases}
1, & \text{if } N_i \leq N_j \
\left(\frac{N_j}{N_i}\right)^p, & \text{if } N_i > N_j
\end{cases}
]
其中:
- (N_i) 是当前正类 (i) 的数量;
- (N_j) 是负类 (j) 的数量;
- (p) 是控制量级的超参数。
举例来说,假设:
- 正类 (i) 是头部类汽车,(N_i = 10000);
- 负类 (j) 是尾部类导弹车,(N_j = 10)。
则有:
[
\mathcal{M}_{ij} = \left(\frac{10}{10000}\right)^{0.8} \approx 0.006
]
这意味着:
- (N_j) 很小;
- (\mathcal{M}_{ij}) 很小;
- 对尾部类 (j) 的惩罚会大幅降低到千分之六左右。
一句话总结:
Mitigation 让尾部类不再被头部类“欺负”。
4.3.3 Compensation Factor
Compensation Factor 的作用是:
专门惩罚“误判”,防止负样本被错判成正样本。
触发条件是:
模型把正类 (i) 误判成 (j),即 (\sigma_j > \sigma_i)。
计算方式如下:
[
\mathcal{C}_{ij} = \left(\frac{\sigma_j}{\sigma_i}\right)^q
]
其中:
- (\sigma_i, \sigma_j) 为预测概率;
- (q) 为控制量级的超参数。
4.3.4 两者协同
| 因子 | 作用 | 效果 |
|---|---|---|
| Mitigation | 减少尾部类负样本的过度惩罚 | 尾部类获得正常学习信号 |
| Compensation | 误检时增强惩罚 | 收紧分类边界,抑制虚警 |
| 协同 | 既平衡梯度、保护尾部类,又避免分类边界过松 | 长尾数据下的稳定学习 |
4.4 其他方法不适用的原因
| 方法 | 核心机制 | 排除原因 |
|---|---|---|
| BAGS | 频率分箱 + 组内 Softmax | 与 YOLO Sigmoid 结构冲突;分箱阈值敏感 |
| Logit Adjustment | 推理阶段 logit 偏移 | 纯推理不治本;无背景针对性 |
| GALA | 类间负梯度平衡 | 检测验证不足;计算开销大 |
| ALA | 数量 + 难度自适应 | 检测验证不足;实现复杂 |
五、最终方案与协同机制
最终损失函数方案为:
[
\text{Loss} = L_{CIoU} + L_{EQLv2} + L_{Focal}
]
| 分支 | 方法 | 职责 |
|---|---|---|
| 回归 | CIoU | 小目标定位,沿用 YOLOv4 方案 |
| 分类 | EQL v2 | 判断“是什么目标”,缓解背景淹没问题 |
| 置信度 | Focal Loss | 判断“有没有目标”,进行难易样本自适应加权 |
| 分类备选 | Seesaw Loss | EQL v2 失效时切换 |
协同逻辑如下:
- Focal Loss 解决“有没有目标”的问题,即前景与背景判断;
- EQL v2 解决“是什么目标”的问题,即汽车、导弹车等类别判断;
- 二者作用于不同分支,互不冲突。
实施策略:
- 前 5 轮使用 BCE 进行预热;
- 第 6 轮启动 EQL v2;
- 必要时切换到 Seesaw Loss。
